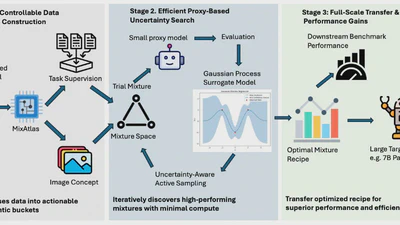
MixAtlas: Uncertainty-aware Data Mixture Optimization for Multimodal LLM Midtraining
Uncertainty-aware data mixture optimization for multimodal LLM midtraining via interpretable domain decomposition.
•
1 min read
Read more
Uncertainty-aware data mixture optimization for multimodal LLM midtraining via interpretable domain decomposition.
Benchmarking dark pattern susceptibility of computer-use agents in realistic UI environments.
Context-driven clarification strategies for ambiguous VQA in a reasoning-focused NeurIPS workshop.
Benchmarking LVLM robustness to spurious correlations and studying generalization beyond the SpuriVerse.
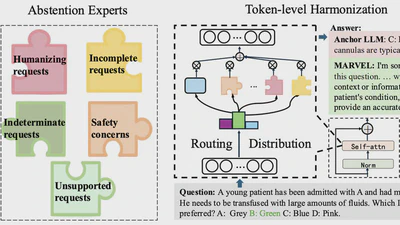
A modular abstention framework for reliable expert LLMs that enables selective abstention from uncertain questions.
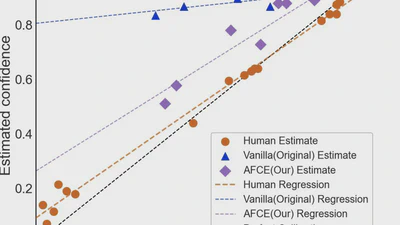
Exploring psychological insights to address overconfidence in LLMs by comparing with human confidence patterns.
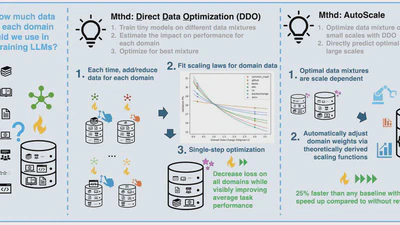
Automatic prediction of compute-optimal data composition for efficient LLM training.
Behavioral analysis and mitigation strategies for overconfidence in large language models.
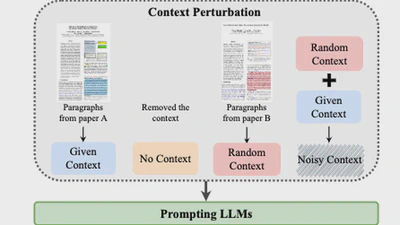
Characterizing LLM abstention behavior in science QA with context perturbations.
Demonstrating that open-weight models can match ChatGPT in low-resource, laboratory-scale AI deployments.